|
|
Ben's UniverseElectronics, programming, and more |
|
| Home | Electronics | Software | Automotive | Miscellaneous |
|
|
|
Ben's UniverseElectronics, programming, and more |
|
| Home | Electronics | Software | Automotive | Miscellaneous |
|
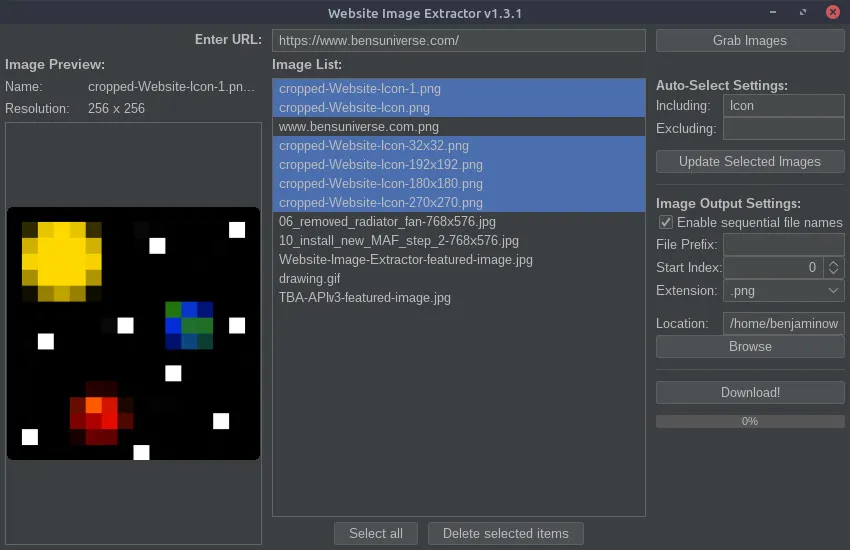
Website Image ExtractorSoftware May 26, 2021 by BenThis Java program is a crude way to extract and download images from the HTML of various websites. Given a URL, the program scans the HTML for that page and looks for image links and other image references. Then, the list of images is presented to the user and unwanted images can be removed. Images can be selected using pattern recognition chosen by the user. Images can be automatically selected or deselected from the master list of images using keyword recognition (explained in detail below). Additionally, the order in which the images should be downloaded can be changed (for images that need to be named in sequential order). Before downloading the images, various output file types can be selected and custom image naming schemes can be used (explained in detail below). Currently, the program does not support extracting images from pages which use JavaScript or other languages to render images after the page is loaded; only image URLs found in the HTML code of the given URL can be downloaded. Additional information and downloads can be found on the GitHub repository or below. URL EntryA URL must first be provided from which to extract the images from. To do this, enter the URL in the top field and select the “Grab Images” button. The images will then be extracted and the other fields in the program can be used for further manipulation. 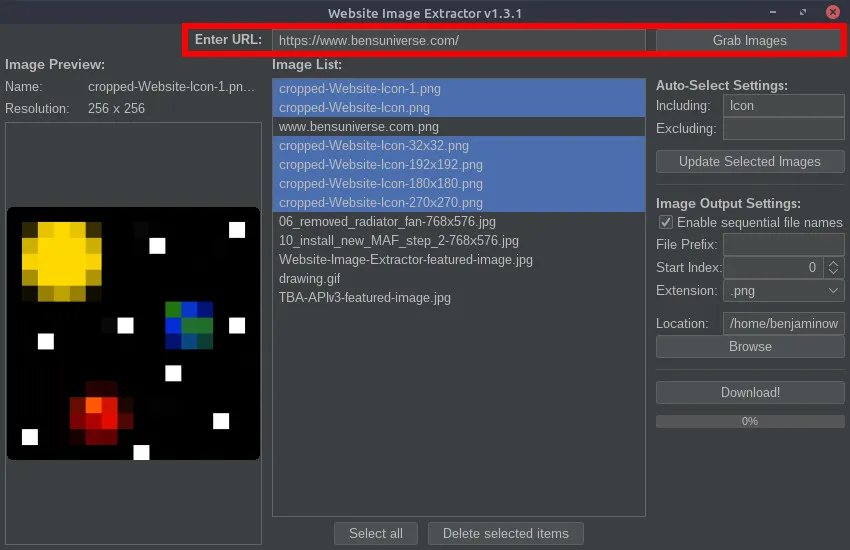 Image Preview and OrderThe leftmost panel in the GUI is reserved for image previews. When an image is selected from the image list (middle panel), a preview of that image will display on the left, also displaying the file name and resolution of the full image. 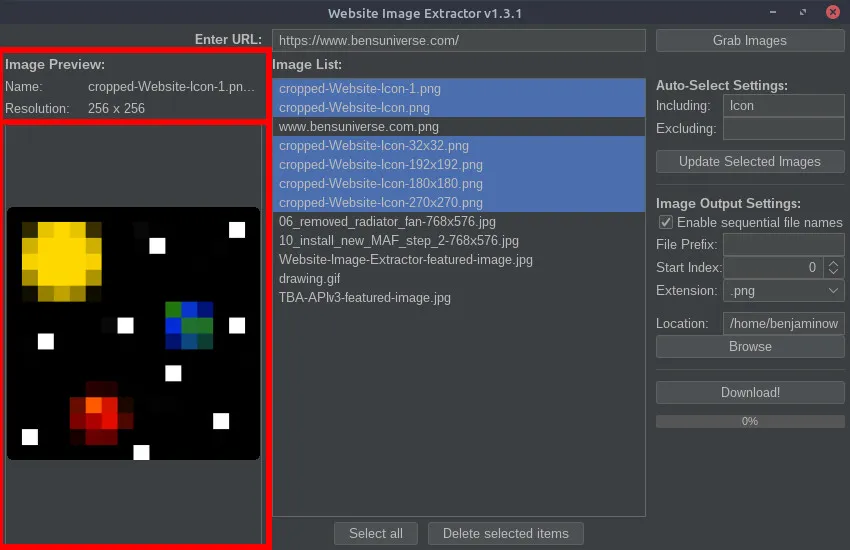 Image ListThe center panel is used to list all of the extracted images and the order they will be downloaded/named in. Images can be dragged and dropped within this list to rearrange the download order (for sequential file names). With images selected, the “Delete selected items” button will remove all selected images from the image list. This removes them from the download list. 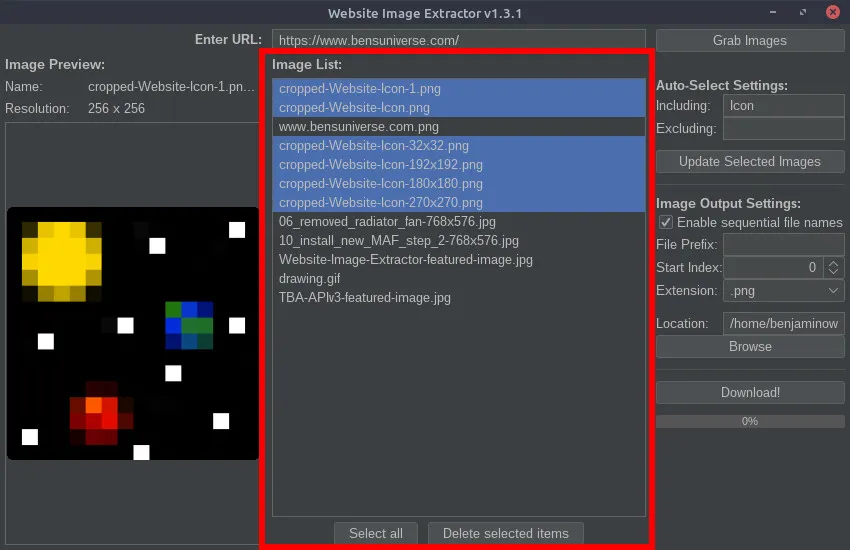 Auto-Select SettingsThe auto-select settings are used to select/deselect images in the image list automatically based on keywords entered by the user. The “Including” field (populated with a comma-separated list) will select all images in the list and check them only if an image name contains ALL of the keywords in the list. The “excluding field” (populated with a comma-separated list) will select all images in the list containing ANY of the keywords in the list. Image Output SettingsThe image output settings are used to determine the output image file name. The “File prefix” field is added at the beginning of the image file name. The “Start index” spinner determines which integer value to begin counting for sequential image names. The “Extension” dropdown is used to select the image file type. If you wish to preserve the original image file names, simply uncheck the “Enable sequential file names” checkbox, and those fields will be disabled and ignored. The “Browse” button can be used to select a different image output location (default is the same location that the program is running in). 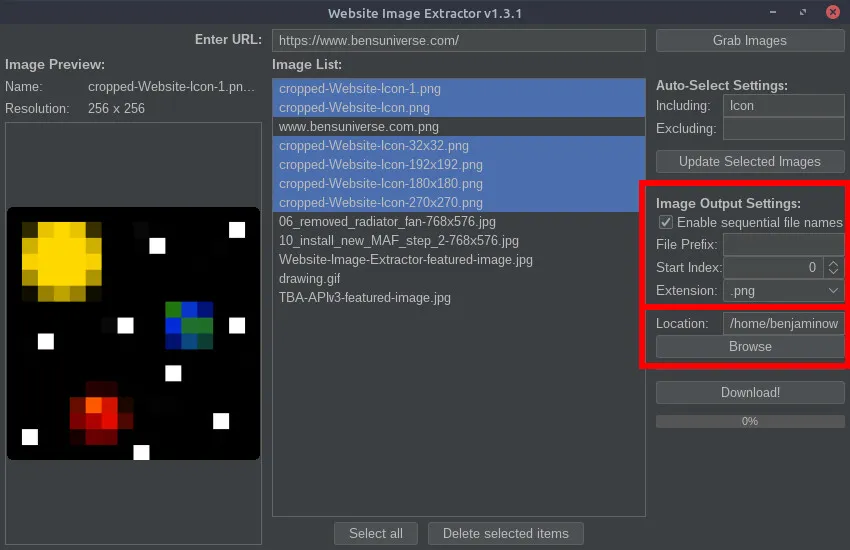 Download ImagesOnce all the settings are chosen, use the “Download!” button to begin downloading all images remaining in the image list. The progress bar will show the current download progress and text will display how many images have been downloaded and the total number of images to download. 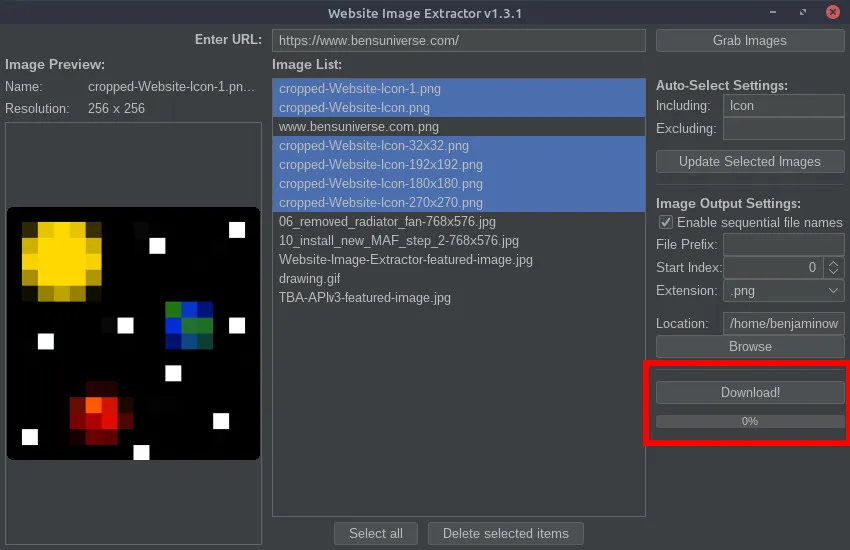 Releases
|
Ben's Universe v7.1.1.1 |
© 2013-2024 Benjamin Owen |
Contact Administrator |